6. Структура гена
Использование рекомбинантных ДНК в огромной степени ускорило развитие молекулярной биологии. В настоящей главе мы опишем в общих чертах некоторые новые методы, связанные с использованием рекомбинантных ДНК, уделив особое внимание тем данным о структуре гена и организации генома, которые были получены с помощью этих методов.
Основной инструмент новой технологии - группа ферментов, узнающих определенную короткую последовательность оснований в ДНК, которая обладает вращательной симметрией, и расщепляющих молекулу ДНК в этой точке. Ниже приведены последовательности, узнающиеся двумя такими ферментами рестрикции, EcoRI из E. coli и Hae III из Haemophilus aegyptius и участки, в которых они расщепляют ДНК:
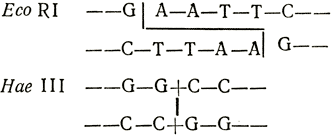
Легко видеть, что при расщеплении ДНК под действием Hae III образуются тупые концы, a Eco RI расщепляет две цепи ДНК наискосок, образуя в результате комплементарные концы. Обработав разные ДНК вторым ферментом, можно получить фрагменты с комплементарными и, следовательно, липкими концами. При соединении фрагментов ДНК из различных источников образуются гибридные молекулы. Определенные фрагменты генома высших организмов можно встроить в геном бактериофага, или автономно реплицирующейся бактериальной плазмиды, которые можно затем использовать в качестве вектора для введения встроенного фрагмента в клетки E. coli. Культивирование таких бактерий приводит к размножению встроенного фрагмента ДНК в астрономических масштабах. Затем можно отделить векторную ДНК и получить достаточное количество соответствующего фрагмента для химического анализа.
Некоторые системы эукариотических клеток синтезируют большое количество какого-то одного белка. Например, инсулин - основной белок, синтезируемый эндокринными В-клетками островков Лангерганса. мРНК, кодирующая этот белок, должна быть наиболее распространенным видом мРНК в этих клетках: ее можно выделить, очистить и с помощью РНК-зависимой ДНК-полимеразы (обратной транскриптазы) синтезировать на ней комплементарную ДНК (кДНК). Эту копию гена можно встроить в подходящий вектор и размножить путем клонирования в E. coli.
На этом этапе было бы важно выяснить, насколько ген, локализованный в ДНК, соответствует исходному гену. Для этого нативную клеточную ДНК обрабатывают ферментом рестрикции и полученные фрагменты разделяют методом электрофореза, переводят путем денатурации в одноцепочечную форму и переносят на мембранный фильтр. кДНК-ген метят in vitro 32Р до высокой удельной радиоактивности, денатурируют и наносят на фильтр. В том месте, где последовательности кДНК комплементарны фрагменту нативной ДНК, они образуют двухцепочечные "гибридные молекулы"; фильтр отмывают от непрореагировавшей кДНК, и с помощью радиоавгографии определяют положение гибридных молекул. Если кДНК представляет точную копию нативного гена, то обработка нативной ДНК и кДНК ферментами рестрикции должна давать одинаковую картину комплементарных гибридных молекул при гибридизации с меченой кДНК.
Очищенные препараты индивидуальных фрагментов ДНК можно секвенировать (расшифровать их последовательность) с помощью простых методов, дающих воспроизводимые результаты. Чаще всего применяется метод, разработанный Максамом и Гилбертом в 1977 г. При работе этим методом ДНК расщепляют, удаляя из нее четыре разных основания. Для удаления оснований используют следующие реакции.
а. Реакция с диметилсульфатом при рН 7,0. При этом происходит преимущественное удаление гуанина по сравнению с аденином.
б. Реакция с диметилсульфатом в кислой среде. При этом удаляется преимущественно аденин.
в. Реакция с гидразином в присутствии пиперидина. При этом удаляются тимин и цитозин.
г. Реакция с гидразином и пиперидином в присутствии NaCl. В этом случае удаляется только цитозин.
Фрагмент ДНК, клонированный в E. coli, метят по концам 32Р и обрабатывают в таких условиях, чтобы атаке подверглось только одно из ста оснований. В результате образуется ряд фрагментов, соответствующих, скажем, расщеплению по каждому аденину. Полученные фрагменты разделяют по длине и, следовательно, по положению удаленных оснований с помощью гель-электрофореза. Одновременный электрофорез препаратов, полученных при четырех различных воздействиях, позволяет исследователю прочитать последовательность оснований в ДНК, как показано на рис. 6.1. Этот метод дает возможность расшифровать последовательности длиной до 100 нуклеотидов; для расшифровки более длинных фрагментов необходимо разрезать исходный фрагмент ферментами рестрикции, расшифровать образующиеся куски по отдельности и затем построить общую картину.
Итак, существуют методы, позволяющие определить последовательность оснований во фрагментах ДНК и проверить соответствие генов их транскриптам. Теперь мы можем коснуться тех данных об организации генома различных организмов, которые были получены с помощью этих методов.
Мы уже видели, что ген или цистрон можно определить как участок ДНК, кодирующий определенный первичный транскрипт, и что ген и его продукт коллинеарны. Накапливается все больше данных о том, что эта схема генетической организации неверна ни для прокариот, ни для эукариот. Оказалось, что во многих вирусах бактерий гены перекрываются и что у высших организмов кодирующая последовательность гена прерывается протяженными нетранслируемыми участками.
А. Исходная последовательность
32Р = TCAGGTTAACG
| Расщепление по А | Расщепление по G |
| 32P = TC | 32P = TCA |
| 32P = TCAGGTT | 32P = TCAG |
| 32Р = TCAGGTTA | 32Р = TCAGGTTAAC |
| Расщепление по Т и С | Расщепление по С |
| 32P = T | 32P = T |
| 32Р = TCAGG | Р = TCAGGTTAA |
| 32Р = TCAGGT | |
| 32Р = TCAGGTTAA |
| A | G | C | C | +T |
| Начало геля | ||||
| - | G | |||
| - | - | C | ||
| - | A | |||
| - | A | |||
| - | T | |||
| - | T | |||
| - | G | |||
| - | G | |||
| - | A | |||
| - | - | C | ||
Рассмотрим вначале явление перекрывания генов на примере бактериофага ∅X174. Геном этого фага представляет собой одноцепочечную ДНК длиной 5375 нуклеотидов, что достаточно для кодирования 1791 аминокислоты или белков с общей молекулярной массой около 200 000. Последние исследования показали, что общая молекулярная масса фагоспецифических белков, содержащихся в зараженных клетках, составляет около 400 000 - примерно вдвое больше теоретически возможного количества. Как же фаг удваивает кодирующую емкость своей ДНК?
С помощью генетического анализа было идентифицировано 10 генов: A, B, С, D, F, G, H, J и К. Расположение этих генов в геноме фага показано на рис. 6.2. Для увеличения кодирующей емкости своей ДНК вирус использует три возможности: перекрывание генов с различными рамками считывания, перекрывание кодонов терминации и инициации и использование различных кодонов инициации и терминации в пределах одной рамки считывания. Мутации гена Е, необходимого для лизиса клетки-хозяина, могут быть локализованы в последовательности нуклеотидов гена D. Однако у амбер-мутантов по гену Е сохраняется способность к синтезу функционально активного продукта гена D, и наоборот. Отсюда можно сделать вывод, что эти два гена должны считываться в разных фазах с различной рамкой считывания. Точно так же ген В содержится в последовательности гена А, а ген К перекрывается с генами А и С.
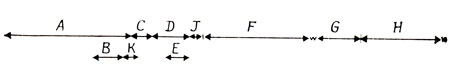
Рис. 6.2. Перекрывающиеся гены фага Х174
Четыре гена, A, C, G и K, кодируют более одного продукта. Кодирующая последовательность гена А включает 1539 оснований. Белок, кодируемый этим геном, участвует в репликации вирусной ДНК. В результате инициации внутри гена происходит транскрипция последних 1023 оснований гена А, и синтезируется А*-белок, функция которого неизвестна. Имеются данные, что в последовательности гена А закодировано еще два белка, но роль терминирующего кодона при их синтезе выполняет не тот кодон, который используется при синтезе продуктов А и А*. Для генов С и К было идентифицировано по два продукта, а для гена G - четыре. По-видимому, их образование объясняется использованием различных участков инициации и терминации.
Наконец, три пары генов, A и C, D и J и B и K, перекрываются на один нуклеотид. Последнее основание терминирующего кодона TGA первого гена в каждой паре служит первым основанием инициирующего кодона ATG второго гена.
Перекрывающиеся гены были обнаружены и в других вирусах; кроме того, имеются косвенные данные об их наличии и у бактерий. Существование таких генов означает, что, определяя ген как последовательность оснований в ДНК, мы должны также указывать рамку считывания для этой последовательности.
Здесь уместно обратить внимание на то, что ген не следует рассматривать просто как кодирующую последовательность, соответствующую ее первичному продукту. Как у прокариот, так и у эукариот транскрипт длиннее, чем соответствующая кодирующая последовательность; лидерная последовательность на 5'-конце мРНК может содержать более 100 оснований, так же как и не кодирующая последовательность на 3'-конце (трейлерная последовательность). Промоторный участок предшествует лидерной последовательности приблизительно на 10 оснований и имеет примерно 7 оснований в длину. Эта последовательность из 7 оснований проявляет высокую степень гомологии у различных бактерий и вирусов. Терминация транскрипции определяется переходом от расположенного в трейлерной последовательности короткого участка, состоящего из GC-пap, к короткому участку из АТ-пар. Теперь можно представить себе основную функциональную единицу генома следующим образом:
При детальном изучении гомологии между различными эукариотическими генами и их транскриптами картина генетической организации оказалась еще более сложной. Помимо нетранслируемых лидерных и трейлерных последовательностей были обнаружены еще другие последовательности внутри структурных генов, не входящие в состав зрелой мРНК. Эти промежуточные последовательности, названные интронами, видимо, широко распространены среди эукариот, а может быть свойственны вообще всем эукариотам, но не обнаружены в прокариотических системах.
В качестве примера рассмотрим ген, кодирующий овальбумин у кур. Овальбумин - главный белок, который синтезируется в клетках яйцевода неполовозрелых кур, получающих эстрогены. Из этих клеток была выделена овальбуминовая мРНК и на ней синтезирована кДНК с помощью обратной транскриптазы. Такой кДНК-"ген" был вставлен в подходящий вектор и клонирован в E. coli. Нативную ДНК из клеток яйцевода и кДНК-"ген" обработали ферментом рестрикции EcoRI, денатурировали и определяли их гомологию с меченой кДНК, как описано выше. Хотя кДНК-"ген" не содержит участков узнавания EcoRI, при обработке нативной ДНК этим ферментом образуется ряд фрагментов, которые гибридизуются с 32Р-кДНК. Отсюда можно сделать вывод, что нативная ДНК содержит какие-то последовательности оснований, включающие участки узнавания EcoRl, которые не представлены в кДНК и, следовательно, в мРНК-транскрипте гена овальбумина.
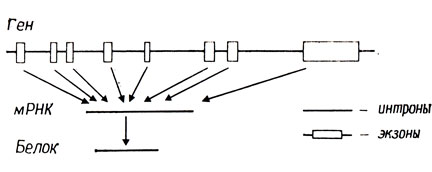
Рис. 6.3. Организация гена овальбумина
Зрелая мРНК овальбуминового гена содержит 1859 оснований, из которых примерно 64 составляют лидерную последовательность, а 634 - трейлерную. В то же время овальбуминовый ген содержит более 7000 пар оснований, так что интроны составляют более 5000 пар оснований, или 70% всего гена. В общей сложности имеется семь интронов, два из которых насчитывают в длину более 1000 пар оснований. Организация этого гена, показанная на рис. 6.3, не является необычной. По существу аналогичные данные были получены при изучении генов глобина у крысы и мыши, генов различных вирусов животных, некоторых типов тРНК дрожжей и митохондральных генов.
Существование интронов, возможно, дает ответ на вопрос, который мучил генетиков на протяжении нескольких лет. Почему у высших организмов содержится примерно в 1000 раз больше ДНК в расчете на гаплоидное ядро, чем у бактерий? Было установлено, что в геноме Е. coli имеется примерно 5000 генов и что организму человека или мыши для нормального функционирования было бы вполне достаточно всего лишь в 10 раз больше генов. Как же объяснить имеющийся избыток ДНК?
Общий состав генома любого организма можно изучать, исследуя кинетику реассоциации. При использовании этого метода ДНК нарезают на фрагменты длиной примерно 300 пар оснований и денатурируют нагреванием при 96°С. При понижении температуры комплементарные одноцепочечные фрагменты могут реассоциировать. Кинетику этого процесса прослеживают спектрофотометрически или путем выделения двухцепочечных молекул на гидроксиапатите. Скорость реассоциации зависит от степени повторяемости данной последовательности в образце. Исследования с применением этого метода показали, что у большинства эукариот примерно 30% генома составляют относительно простые последовательности, представленные в количестве 102 - 106 копий. Высокоповторяющиеся последовательности обнаруживаются главным образом в гетерохроматических и центромерных участках. Остальные 70% генома состоят из уникальных последовательностей, количество ДНК в которых достаточно примерно для 106 генов.
Мы видели на примере овальбуминового гена, что на долю интронов может приходиться до 70% ДНК. Гилберт предположил, что наличие интронов - общий принцип организации генома у эукариот; он считает, что они составляют 80 - 90% всех уникальных последовательностей ДНК. Именно он предложил называть последовательности, которые входят в состав зрелой мРНК, экзонами, так как они экспрессируются, а те промежуточные последовательности, которые хотя и транскрибируются, но затем вырезаются из транскрипта до того, как он выходит из ядра, интронами. Если исходить из максимального значения содержания интронов в геноме, то последовательностей экзонов хватит на 105 генов. Если допустить, что промоторные, лидерные, трейлерные последовательности и спейсеры составляют 25% экзонов, то наиболее вероятно, что общее число генов составляет 75 000.
Уже давно было известно, что в ядрах эукариот содержится значительное количество лабильной высокомолекулярной РНК, комплементарной ДНК. В состав этой гетерогенной ядерной РНК (гяРНК) входят последовательности оснований зрелой мРНК, однако большая часть этой РНК не выходит из ядра. В настоящее время есть основания думать, что гяРНК представляет собой продукт транскрипции интронов и экзонов. Затем интроны вырезаются, а экзоны соединяются между собой. В какой-то момент перед выходом из ядра к 5'-концу мРНК присоединяется остаток метилированного гуанина, называемый "колпачком" (cap), а к 3'-концу присоединяется примерно 200 остатков адениловой кислоты. Теперь зрелая мРНК может пройти через ядерную мембрану и быть использована в качестве матрицы для синтеза белка в цитоплазме.
|
ПОИСК:
|
При использовании материалов активная ссылка обязательна:
http://genetiku.ru/ 'Генетика'