Приложение 1
Методы подсчета генных частот
В этой книге рассматриваются лишь основные принципы подсчета частот генов (разд. 3.2). Более подробно эти вопросы изложены в работах Рэйса и Сэнгера [166], Муранта [144] и других. Мы начнем с простейшего примера.
Одна пара аллелей: все три генотипа имеют разное фенотипическое выражение. В этом случае можно идентифицировать каждый отдельный аллель (М или N), и частота гена подсчитывается прямо. В качестве примера можно привести изоантигены группы крови MN:
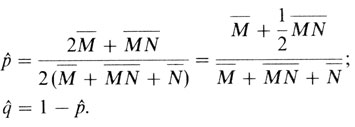
Можно вычислить и дисперсию
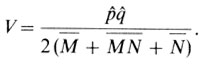
Генные частоты рˆ и qˆ используют для тестирования соответствия наблюдаемых фенотипических частот их ожидаемым значениям по закону Харди - Вайнберга. Применяя следующую формулу, можно избежать вычисления ожидаемых значений
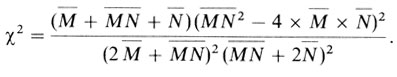
Этот метод подсчета пригоден и в том случае, когда имеется больше двух аллелей и каждому генотипу соответствует определенный фенотип; например, для полиморфных вариантов кислых фосфатаз эритроцитов.
Одна пара аллелей: по фенотипу можно определить только два разных генотипа. Проблема усложняется, если один из двух аллелей доминирует, т. е. гетерозигота фенотипически совпадает с одной из гомозигот. В этом случае по частоте рецессивных гомозигот можно судить о частоте соответствующего гена.
Частота гомозигот составляет q2. Примером может служить группа крови Диего (Diego) (разд. 7.3.1). У американских индейцев и в монголоидных популяциях имеются два фенотипических класса: обнаруживающие положительную реакцию агглютинации с сывороткой анти-Diа и необнаруживающие таковой. Семейные исследования показали, что отрицательный тип реакции является рецессивным признаком
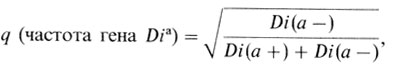
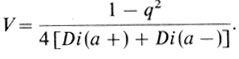
В этом случае не остается ни одной степени свободы для тестирования равновесия Харди - Вайнберга.
Если имеется aнти-Dib сыворотка, то можно идентифицировать гетерозигот и вычислить частоту гена тем же способом, что был описан выше для групп крови MN.
Более двух аллелей: не все генотипы можно различить по фенотипу. Специальный случай групп крови АВ0 уже обсуждался в разд. 3.2.2.
Метод подсчета, основанный на принципе максимального правдоподобия. Мы сталкиваемся с общей проблемой оценки априорно неизвестного параметра по эмпирическим данным. Согласно Фишеру, оценка должна удовлетворять следующим условиям:
а) она должна быть состоятельной. Это означает, что с увеличением числа наблюдений оценка сходится стохастически (по вероятности) к параметру;
б) оценка должна быть достаточной. Это означает, что из имеющихся данных нельзя извлечь дополнительное знание о параметре с помощью вычисления других статистик;
в) оценка должна быть эффективной, т. е. извлекать из данных максимально возможное количество информации. Дисперсия должна быть минимальной.
Обычно проблема оценки лучше всего решается на основе принципа максимального правдоподобия, предложенного Фишером. Рассмотрим сначала простой пример.
Вероятность наступления n1 событий, каждое из которых имеет вероятность р, и n - n1 событий, каждое из которых имеет вероятность 1 - р, в соответствии с биномиальным распределением равна
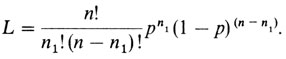
Чтобы найти значение р, для которого эта вероятность максимальна, следует приравнять нулю первую производную L по р. Для удобства вместо L обычно максимизируют ее логарифм
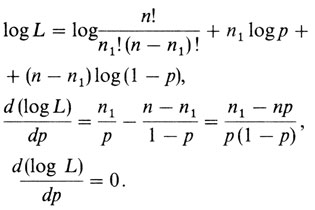
Следовательно, р = n1/n - результат, который интуитивно очевиден. Это означает, что n1 = nр, т. е. для биномиального распределения наиболее вероятное значение параметра есть такое, для которого ожидаемое значение совпадает с наблюдаемым. Приведем без вывода формулу для дисперсии (в случае больших выборок) этой оценки параметра рˆ, которая получается подстановкой оценки максимального правдоподобия параметра р в выражение для отрицательной обратной второй производной L по р. В нашем случае
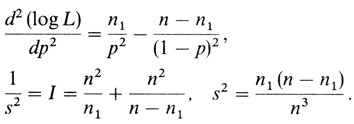
Это выражение для s2 можно получить более удобным способом. Подстановка р = n1/n и 1 - р = (n - n1)/n в общую формулу для дисперсии биномиального распределения V = p (1 - р)/n дает тот же самый результат.
Рассмотрим теперь более общий случай [150]. Пусть x будет случайной переменной, распределение которой зависит только от р. Тогда функцию плотности вероятности для x можно записать как f(x; p). Пусть имеются и реализиций (выборка объема n) x1, х2, ..., хn переменной x. Тогда вероятность такой выборки можно записать следующим образом:
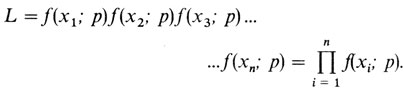
Если в это выражение подставить конкретные наблюдаемые выборочные значения и рассматривать его как функцию от р, то получится функция правдоподобия данной выборки. Оценка максимального правдоподобия находится путем решения относительно р следующего уравнения:
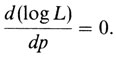
Дисперсию этой оценки получают путем вычисления второй производной и взятия отрицательной обратной величины ее математического ожидания (математическое ожидание обычно обозначается символом E)
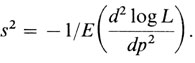
1/s2 называется также информацией о р или Ipp.
Простой метод подсчета генов, представленный выше на примере групп крови MN, как раз и дает оценку максимального правдоподобия. Вычисления становятся несколько сложнее, когда имеется более двух аллелей и по фенотипу нельзя идентифицировать все генотипы, как, например, для системы групп крови АВ0. В этом случае многими авторами были предложены разные формулы для получения оценок максимального правдоподобия.
Однако метод Бернштейна с поправками оказался практически эквивалентным. Следовательно, формулы, полученные из уравнений максимального правдоподобия, можно использовать для вычисления дисперсий оценок по Бернштейну;
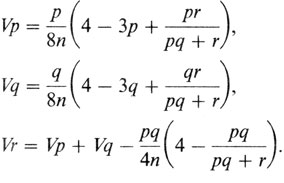
Здесь n означает объем выборки (для всех четырех групп крови вместе).
Вычисление частот аллелей групп крови системы АВ0 по методу Бернштейна. Бернштейн при исследовании генетической основы системы АВ0 (разд. 3.2) разработал метод оценки частот аллелей групп крови этой системы. Затем он усовершенствовал свой метод, получая сначала предварительные оценки частот р', q', r', а затем поправляя их для вычисления точных генных частот р, q, r:
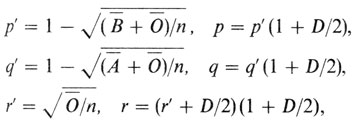
где D = 1 - (p' + q' + r'). Было показано, что оценки, получаемые с использованием этого усовершенствованного метода Бернштейна, практически идентичны оценкам максимального правдоподобия.
Пример: оценка генных частот с помощью подсчета генов. Рэйс и Сэнгер [166] привели следующие фенотипические частоты для жителей Лондона, Оксфорда и Кембриджа:
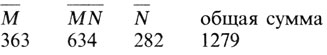
Следовательно, в соответствии с уравнением (П. 1.1) частота р аллеля М и частота q аллеля N равны:
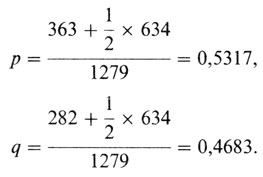
Отсюда вытекает р2 = 0,2827; 2pq = 0,4980; q2 = 0,2193.
Чтобы вычислить ожидаемые генотипические частоты (Е), эти цифры следует умножить на 1279 - общее число обследованных жителей
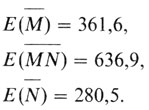
Теперь сравним эти ожидаемые значения с наблюдаемыми
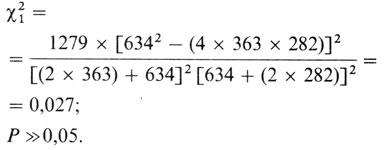
В данном случае нет статистически значимого различия между наблюдаемыми и ожидаемыми генными частотами.
Пример: оценка частот аллелей системы АВ0 [711]. Для 21104 жителей Берлина было найдено следующее распределение по группам крови:
А¯ = 9123,
В¯ = 2987,
0¯ = 7725,
АВ¯ = 1269.
В соответствии с усовершенствованным методом Бернштейна это дает следующие результаты (подробнее в разд. 3.2.2):
p = 0,287685 ± 0,002411,
q = 0,106555 ± 0,001545,
r = 0,605760 ± 0,002601.
Было показано, что метод максимального правдоподобия приводит к точно таким же результатам [711]. Дисперсии по методу максимального правдоподобия получились следующими:
Vp = 0,000005811,
Vq = 0,000002386,
Vr = 0,000006763.
Для получения стандартных отклонений нужно извлечь квадратные корни из этих дисперсий.
Точно так же, как было показано для групп крови MN, по частоте аллелей А, В и 0 можно вычислить ожидаемые генотипические частоты и сравнить их с наблюдаемыми частотами по критерию хи-квадрат.
Еще более сложные проблемы возникают при анализе групп крови Rh и вообще при анализе всех систем, в которых вместе наследуется много разных комбинаций антигенов. Для этих случаев опубликованы или упомянуты в публикациях компьютерные программы. Для системы Rh можно воспользоваться публикациями [585; 586]. Рядом авторов предложены правила вычисления частот аллелей и гаплотипов для системы HLA [554; 738; 779; 805; 962]. Находит свое применение также система ALLTYPE [789].
Однако неадекватность составления выборки не компенсируется обработкой на компьютере. Все упомянутые до сих пор методы основаны на предположении, что выбор индивидов проводился независимо, т. е. выбор какого-либо одного индивида не увеличивает и не уменьшает шанс быть выбранным для любого другого индивида в популяции. Это правило нарушается, например, при сборе данных о родственниках. Однако нельзя сказать, что выборки, содержащие родственников, всегда бесполезны для вычисления генных частот. Но включение родственников в выборку должно быть обязательно отмечено вместе со степенью их родства, и для анализа должны использоваться специальные статистические методы [211].
|
ПОИСК:
|
При использовании материалов активная ссылка обязательна:
http://genetiku.ru/ 'Генетика'