§ VI.3. О возникновении кода
Возможность существования гиперцикла, рассмотренного в § VI.1 и VI.2, зависит, очевидно, от наличия кода и аппарата трансляции. Такой код потребовался бы для любой модели, которая использует соответствие между инструктирующей способностью, присущей нуклеиновым кислотам, и функциональным потенциалом трехмерных белковых структур. Проблема возникновения уникального кода (существование которого является фактом) носит, таким образом, более общий характер, нежели вопрос о существовании какой-либо конкретной модели для самоподдерживающегося каталитического гиперцикла.
Не содержит ли современная таблица генетического кода (табл. 2) какого-либо намека на свое происхождение? Эта проблема тщательно анализировалась рядом авторов, и в частности в монографии А. Вёзе [107]. Можно напомнить следующие важные факты:
1. Все, что нам сегодня известно, указывает на универсальность кода.
2. Маловероятно, что современный триплетный код развился из предшествующего дублетного или синглетного кода [108]. Как указал Ф. Крик [108], изменение величины кодона повлекло бы за собой полную потерю информации, накопленной к тому времени, если только при этом расстояние между кодонами в сообщении не оставалось неизменным или же если не существовало простой процедуры перевода информации из старой последовательности кодонов в новую. Это не исключает возможности того, что отдельные единицы в различных положениях кодона могут иметь разный вес в смысле своего информационного содержания.
3. Гипотеза виляний, предложенная Криком [22], дает объяснение сильной вырожденности кода в отношении третьего положения в кодоне (3'-конец). Она объясняет вырожденности кода вырожденностью в комплементарности оснований на 5'-конце антикодона и 3'-конце кодона
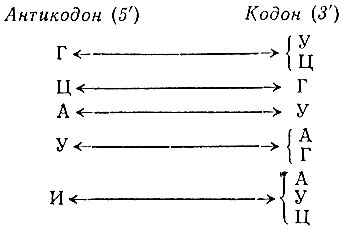
что приводит к эквивалентности У и Ц, а также А и Г (или А, У и Ц) в третьем положении кодона.
4. Среднее положение в кодирующем триплете, по-видимому, играет большую роль в определении природы соответствующей аминокислоты (гидрофобная, полярная или заряженная). Эта закономерность, возможно, имеет значение для возникновения кода, основанного на каких-то специфических взаимодействиях между нуклеотидами и аминокислотами [109].
5. Код, по-видимому, отражает принцип оптимизации, как указал И. Рехенберг, который провел формализованное исследование этого вопроса [110]. Для большинства кодонов изменение одной из трех букв приводит к минимальному изменению природы аминокислот; таким образом, это тоже может отражать упомянутую закономерность в отношении среднего положения. Аминокислоты снова были разделены на четыре класса: гидрофобные, полярные, положительно заряженные и отрицательно заряженные. Сюда можно добавить функциональные корреляции, например кислотные или основные функции боковых цепей аминокислот, а также структурные соответствия, например сходство Фен-Тир и т. д. Любой принцип оптимизации имел бы особое значение для случайного возникновения кода (см. ниже) и оказывал бы влияние на выбор вариантов в процессе нуклеации. Он привел бы также к тому, что информационное содержание последовательности оснований стало бы до некоторой степени инвариантным (если говорить о классах аминокислот) по отношению к перекрывающемуся считыванию кода (в эпоху плохо адаптированных ферментов перекрывания, вероятно, случались довольно часто).
6. Восемь кодонов, состоящих из А и У, дают гораздо большее разнообразие функций, чем восемь триплетов из Г и Ц (табл. 2). Ф. Липман [111] впервые обратил внимание на этот факт и на его возможную связь с простым механизмом возникновения кода. В пользу этой точки зрения имеются следующие аргументы:
а) вероятно, очень большая распространенность А по сравнению с У, Ц и Г в условиях примитивной Земли, что приводит к большей распространенности АУ-пар по сравнению с ГЦ-парами;
б) большая стабильность ГЦ-пар по сравнению с АУ-парами, что позволяет впоследствии ГЦ замещать АУ, если это дает селективное преимущество;
в) недавно найденное [112] относительно высокое содержание АУ-пар в рибосомной РНК митохондрий и хлоропластов, которая, возможно, не подвергалась сильному давлению отбора (в соответствии с гипотезой, что обе эти клеточные органеллы представляют собой прокариотические включения в клетках эукариотов);
г) и, наконец, прагматический аргумент; с точки зрения статистики, нуклеация любого кода происходит легче всего в том случае, когда число различных классов единиц сведено к минимуму.
Как могло возникнуть определенное соответствие между аминокислотами и кодонами или антикодонами?
Без сомнения, простейшее объяснение состояло бы в том, что между этими двумя системами единиц существует специфичное взаимодействие. Было предложено множество моделей такого взаимодействия [113]: отдельный кодон - аминокислота; аминокислота, входящая в щель между двумя спаренными триплетами кодон - антикодон; аминокислота, которая опознается большой сложно свернутой адапторной молекулой - предшественником тРНК [38, 39]; предполагали также, что такие предшественники аминоацил-тРНК имели повышенную стабильность (Л. Оргел, личное сообщение). Ценность любой такой модели зависит исключительно от наличия подтверждающих ее экспериментальных данных, а они до сих пор очень скудны.
Очевидно, можно значительно повысить специфичность узнавания аминокислот нуклеотидами, если не ограничиваться взаимодействием отдельных единиц, т. е. аминокислотой и кодоном или антикодоном. Одной из причин того, почему тРНК является сравнительно большой молекулой, может быть либо необходимость достаточно характерной третичной структуры, обеспечивающей узнавание ее каким-то ферментом, либо то, что сама протяженная структура обладает способностью к узнаванию, как это свойственно молекуле фермента. Обе эти возможности будут обсуждаться в связи со "случайными" моделями. Остается еще одна трудность: как предотвратить случайное соответствие, потому что все перестановки в области антикодона могут, по-видимому, произойти без изменения адапторной структуры.
Бессмысленно развивать модель, основанную лишь на гипотетическом, до сих пор экспериментально не установленном взаимодействии. Во всяком случае, для однозначно определенного начала потребовались бы очень специфичные взаимодействия (q, близкое к единице), но очень сомнительно, существуют ли вообще достаточно сильные взаимодействия, обеспечивающие прямое соответствие между антикодонами и аминокислотами*. Таким образом, встает законный вопрос:
* (Имеется еще другое соображение: если бы существовало такое изначальное взаимодействие между, аминокислотами и кодонами, то можно было бы предположить, что ферменты эволюционируют, используя это взаимодействие, но это привело бы к возможности обратного считывания от белка к нуклеиновой кислоте (что противоречит "центральной догме" молекулярной биологии). Хотя есть ферменты, допускающие обращение транскрипции (РНК → ДНК), нет никаких данных (и их даже трудно представить), что такое обращение считывания может иметь место для трансляции, хотя, если бы такой механизм существовал, он давал бы известные преимущества.)
Если специфические взаимодействия отсутствуют, то не могло ли однозначное кодовое соответствие появиться из случайных комбинаций аминокислот с антикодонами?
Любое специфическое взаимодействие между кодоном (или между любой неразрывно связанной с кодоном структурой) и аминокислотой - когда бы оно ни существовало - может повысить вероятность в остальном ненаправленного начала трансляции. Нас опять-таки интересует не столько конкретная (спекулятивная) модель, сколько оценка вероятностей для случайного возникновения (или нуклеации) возможных предшественников ныне известной адапторной системы узнавания. Другими словами, мы хотим знать, насколько сложной должна быть система, чтобы в ней с ненулевой вероятностью могла возникнуть однозначная трансляция, предполагая, что никакое специфическое взаимодействие не влияет на выбор кодового соответствия.
Предположим, что имеются только такие взаимодействия, существование которых экспериментально обосновано. Например, мы знаем, что способностью к очень специфичному узнаванию тРНК или подобных ей структур обладают трехмерные белковые структуры. Мы знаем также, что аминокислоты могут быть активированы (например, при помощи АТФ) и присоединены к нуклеотидной последовательности, но мы не знаем никакого специфического и изначального взаимодействия между аминокислотами и антикодонами, которое удовлетворительно реализовалось бы без помощи ферментов.
Простейшая модель "случайного" начала трансляции основывается на существенно равных априорных вероятностях различных соответствий между аминокислотами и кодонами или антикодонами. Таким образом, любая из аминокислот a, b, c ... может a priori связаться с любым из адапторов А, В, С ..., так что соответствие а - А, b - B и т. п. отражает только конечный исход (к которому ретроспективно и приспособлены обозначения). Рассмотрим три модели, к которым относится это допущение и для которых поэтому возможен общий подход:
1. Аминокислота узнается третичной структурой (например, щелью) полинуклеотида, похожего на предшественник тРНК. Антикодон локализуется в открытой петле; но он может не участвовать в узнавании (или не определять его) и фиксации аминокислоты на адапторе, так что a priori данной аминокислоте может быть сопоставлен любой триплет.
2. Модель, аналогичная первой, с той разницей, что аминокислота заменена олиго- или полипептидом (второй адаптор), концевая аминокислота которого должна быть активирована. Такое взаимодействие полинуклеотида с полипептидом может быть гораздо более тесным и специфичным, чем взаимодействие с отдельной аминокислотой, но, как и прежде, для каждой данной взаимодействующей структуры полипептида и полинуклеотида можно произвести любую подстановку концевой аминокислоты и доступного антикодона.
3. Модель, сходная со второй моделью, в которой, однако, полипептиды обладают ферментативной активностью (как предшественники аминоацилсинтетаз) - специфично узнают свободную аминокислоту (или олигопептид), которая должна присоединяться к данной адапторной структуре; эта модель снова допускает любые возможные комбинации антикодон - аминокислота.
В любой из этих моделей мы имеем λ единиц, т. е. аминокислоты a, b, b, ..., которые нужно поставить в соответствие кодонам А, В, С, ... с помощью адапторов А', В', С' (комплементарных А, В, С ...). Имеется всего λ2 возможных соответствий, например, для λ = 2:аА', аВ', bА'и bВ'. Различные соответствия возможны потому, что А', например, согласно нашему допущению, представляет собой целый класс адапторов, которые все имеют один и тот же антикодон, соответствующий А, но в остальном могут взаимодействовать совершенно по-разному с различными аминокислотами или активирующими ферментами. Предполагается, что все соответствия имеют равные априорные вероятности. Рассмотрим теперь элемент объема*, в котором имеется λ таких соответствий. Тогда вероятность (Р) найти данный набор соответствий будет обратно пропорциональна числу всех возможных наборов, которое в свою очередь равно числу всех сочетаний с повторениями из λ2 элементов по λ:
* (Величина этого элемента объема подобрана исходя из условия, что в нем имеется λ соответствий. В этом объеме, конечно, находится гораздо большее число полипептидных и полинуклеотидных последовательностей. Они, однако, не участвуют в фиксации аминокислот на адапторе. Важно лишь следующее соответствие для данной последовательности должно быть специфичным или, лучше, специфичные соответствия должны быть определяющими. В противном случае данная комбинация не будет однозначной и на все будет накладываться довольно значительный "шум".)
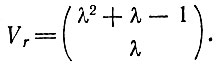
Сюда входят также те комбинации, в которых все соответствия относятся к одному типу, например а - А', а также те, в которых данный адаптор соединен со многими различными аминокислотами: а - А', b - А', с - А' ..., или наоборот; короче говоря, допускается любой набор соответствий. Это весьма крайнее (и, по-видимому, не очень реалистичное) допущение, но оно сделано для того, чтобы получить нижний предел для вероятностей, так что любое отклонение может только усилить нашу аргументацию.
Среди всех соответствий имеется λ! уникальных, т. е. таких, в которых данная аминокислота соединена только с одним (анти-) кодоном и наоборот. Таким образом, вероятность найти элемент объема, где имеется какое-либо уникальное соответствие, равна
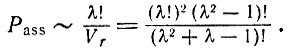 (VI.6)
(VI.6)Такой элемент объема начнет - возможно, с помощью катализатора - однозначно транслировать нуклеотидные последовательности в последовательности аминокислот, но только до тех пор, пока в рассматриваемом элементе объема поддерживается данная конкретная "флуктуация" соответствий. Чтобы стабилизировать этот тип трансляции, мы должны найти среди нуклеотидных последовательностей такие, которые после трансляции усиливают использование того же кода. Только такой ансамбль нуклеотидов представлял бы собой стабильный и воспроизводимый источник информации для кода и аппарата трансляции (состоящего из определенного набора адапторов и активирующих ферментов). Для того чтобы отбор благоприятствовал именно данному ансамблю, подавляя другие конкурирующие системы, особенно те, которые не однозначны и поэтому всегда дают некоторое воспроизведение нонсенсов, в данной системе должен возникнуть самоусиливающийся гиперцикл, описанный в первых двух параграфах этой главы*.
* (Одна возможность состоит в том, что адаптеры с самого начала были достаточно протяженными нуклеотидными структурами, которые могли осуществлять двойные функции:
а) действовать как специфичные адапторы, имея петлю антикодона, и могли специфично узнаваться активирующими ферментами;
б) специфичная информация (Ii), содержавшаяся в их последовательностях, кодировала бы ферменты Еи которые являлись членами гиперцикла. Однако на этом этапе нельзя сделать определенного вывода о сложности системы, в которой могла происходить нуклеация; в нее могли входить также адапторы с короткой цепью, распространенность которых a priori высока.)
Вероятность найти такой набор нуклеотидов, который будет усиливать определенную функцию трансляции, зависит от тех же предпосылок, что и вероятность найти набор белков, выполняющий эту функцию. Если полинуклеотиды каким-то образом транслируются, им будет соответствовать некий набор случайных полипептидных последовательностей; таким образом, мы должны исходить из тех же предположений, как и в том случае, когда мы искали λ специфичных "координаторов", однако теперь не будет вырожденности λ!, потому что система должна усиливать одно из λ возможных однозначных соответствий. Если концентрации случайных нуклеотидных последовательностей близки к концентрациям случайных полипептидов, вероятность найти определенный набор в данном элементе объема снова будет равна величине, обратной "числу всех сочетаний с повторениями" из λ2 элементов по λ.
Тогда совместная вероятность приближенно равна
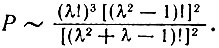 (VI.7)
(VI.7)Эту закономерность иллюстрируют следующие примеры:
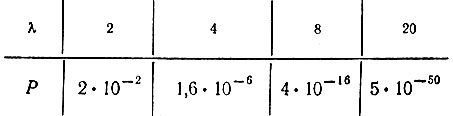
Совместная вероятность содержит также множитель, описывающий отношение концентраций полинуклеотидных и полипептидных последовательностей. Далее, сделаны совершенно нереалистичные допущения, например одинаковые априорные вероятности для всех последовательностей, которые приводят к тому, что эта формула дает лишь грубую оценку некоторых величин.
Есть еще один важный пункт: процедура состоит в том, чтобы найти вероятность существования и воспроизведения определенной функции (т. е. соответствия аминокислота - кодон) в популяции случайных полипептидов, но не в том, чтобы найти вероятность совместного нахождения определенных последовательностей. Функция может быть представлена очень большим числом различных полипептидных последовательностей, таким большим, что в действительности эти последовательности можно найти практически в любой случайной популяции (см. эксперименты С. Фокса [102] и его сотрудников, которые показали, что в любом случайном наборе полипептидов можно обнаружить функцию, моделирующую активность химотрипсина). Назовем эту вероятность p - независимо от ее специального вида. Тогда та же вероятность наличия той же функции (после трансляции) будет относиться и к популяции случайных нуклеотидных последовательностей (имеющих равные концентрации). В первом случае мы все же имеем λ! однозначных выборов для соответствий, тогда как второй выбор должен совпадать с первым. Совместная вероятность тогда становится равной λ!p2. Мы ищем вероятность совпадения функций, а не последовательностей. Если бы мы искали вероятность наличия определенной нуклеотидной последовательности, которая после трансляции дала бы полипептидную последовательность, точно совпадающую с данной (с которой начался определенный тип трансляции), то эта вероятность была бы порядка 10-130 (для 100 аминокислот, принадлежащих к 20 классам), подтверждая аргументацию Вигнера (см. гл. I).
Однако в подобных оценках таится достаточно ловушек, чтобы заставить нас отказаться от более подробного анализа, пока не накопится больше экспериментальных данных о каталитических функциях полипептидов со случайными последовательностями. Основной довод - что определенная каталитическая специфичность не является уникальным свойством одной или нескольких данных последовательностей, а встречается довольно часто в любой случайной популяции достаточно большого размера - может быть проверен экспериментально (см. гл. VII). Даже не имея таких данных, мы можем оценить, при какой степени сложности однозначная трансляция, начинающаяся со случайных флуктуаций, становится совершенно невероятной.
В отношении вероятности случайного начала трансляции можно сделать следующие выводы (см. также численные примеры, приведенные после уравнения VI.7). Бинарная система трансляции может возникнуть, по-видимому, очень легко, но с функциональной точки зрения двух единиц (или классов единиц) было бы недостаточно для обеспечения специфичности. Сделано предположение, что четыре класса единиц - минимум, необходимый для начала процедуры оптимизации в эволюции кода. Вероятность нуклеации четырехбуквенной трансляции еще имеет приемлемую величину. Вероятность, отвечающая восьмибуквенному коду, находится, по-видимому, на пределе того, что представляется осуществимым при разумных концентрациях в пределах Земли и в масштабах времени, на протяжении которого происходила ранняя эволюция (оно, вероятно, значительно меньше 109 лет ∼3⋅1016 с). Восьмибуквенный код могла бы обеспечить система АУ. Далее, восьми аминокислот, по-видимому, достаточно для построения функционально специфических последовательностей любого типа. Не обязательно даже начинать, имея только 8 аминокислот, - можно иметь 8 (или меньше) классов функционально родственных молекул. То же самое справедливо для инструктирующего кода, который мог бы начаться с вырожденных классов и развиваться дальше в соответствии с некоей процедурой оптимизации [110]. Поэтому вполне возможно, что тот конкретный код, который мы находим теперь, возник из случайной флуктуации; следовательно, нет необходимости предполагать существование очень специфичного (прямого или непрямого) взаимодействия между кодоном и аминокислотой. Если это верно, то любая независимо эволюционирующая система ("где-то" во Вселенной или "когда-нибудь" в лаборатории) могла бы использовать другой код, но он был бы основан на таких же принципах. Далее, с самого начала теперешний код мог быть и не единственным; однако нелинейная жесткая процедура отбора гарантирует его универсальность.
С другой стороны, следует подчеркнуть, что в настоящее время единственно правильным может быть утверждение: "Нельзя исключить возможность того, что ...". Поэтому единственный смысл сделанных выше оценок состоит в том, чтобы найти, при какой степени сложности случайное начало становится слишком маловероятным. Оргел выдвинул интересную идею о том, что в процессе эволюции происходила не нуклеация всего словаря (например, из 4 или 8 букв), а поэтапный или непрерывный переход к образованию системы трансляции, который начался с 1-2 предпочтительных соответствий между адаптором и аминокислотой. Наличие таких "изначальных" соответствий всегда будет увеличивать вероятность нуклеации самовоспроизводящейся функциональной сети.
Наконец, можно задать вопрос: как понимать такое "случайное начало" трансляции с точки зрения физики?
Здесь снова надо прибегнуть к критерию ценности в теории отбора, который аналогичен принципу Пригожина - Глансдорфа в нелинейной необратимой термодинамике. В самоорганизующейся системе с селекционным поведением (что определяется известными свойствами реакционной системы и наложением дополнительных внешних ограничений) появление нового вида иди ансамбля с большей селективной ценностью всегда будет приводить к неустойчивости, т. е. к разрушению прежнего стационарного состояния и построению нового стационарного состояния, в котором доминирует вид или ансамбль с наибольшей селективной ценностью. "Успех" нового вида подчинен определенным ограничениям и может корректно описываться стохастической теорией.
Мы приходим к следующему заключению.
Нуклеиновые кислоты обеспечивают выполнение необходимого условия самоорганизации. Однако, чтобы создать высокую информационную емкость, они нуждаются в каталитически активном связывающем факторе, имеющем большую способность к узнаванию. "Информация" приобретает свой смысл только посредством функциональной корреляции. Любая флуктуация, в присутствии потенциальных связывающих факторов ведущая к однозначной трансляции, и ее усиление посредством образования каталитического гиперцикла создает колоссальное селективное преимущество и вызывает распад прежнего стационарного состояния с некоррелированным самовоспроизведением.
Вследствие такой нестабильности нуклеация этой функциональной корреляции (мы можем назвать ее возникновением жизни) оказывается неизбежным событием - если благоприятные условия существования потока свободной энергии поддерживаются в течение достаточно длительного времени. Это первичное событие не уникально. В любом случае код станет универсальным вследствие нелинейной конкуренции.
|
ПОИСК:
|
При использовании материалов активная ссылка обязательна:
http://genetiku.ru/ 'Генетика'