Молекулы жизни
Слово "белок" уже не раз встречалось на нашем пути, но еще не было случая свести с ним более короткого знакомства. Что же такое белок?
Белковая молекула состоит из длиннейшей цепи:
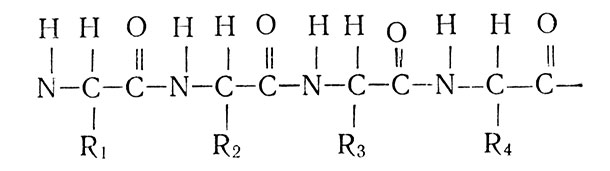
Атом азота, два атома углерода чередуются подобно белым и черным клавишам рояля. Но что скрывается за символом R=(R1, R2, R3 и т. д.)? Так обозначают радикалы-аминокислоты. Сколько их? Как они устроены? Сегодня любой студент, мало-мальски знакомый с основами биохимии, без особого труда расскажет вам об этом.
Белок легко разложить на составные части. Это делают путем гидролитического расщепления, или, как принято говорить, гидролиза. Вот тогда-то связи между группами CO-NH (их называют пептидными) разрываются и на свободе появляются двадцать аминокислотных остатков. Концы их немедленно насыщаются: N - атомами водорода (NH2), а CO - ионами OH, которые всегда есть в воде. И аминокислота предстает в таком виде:
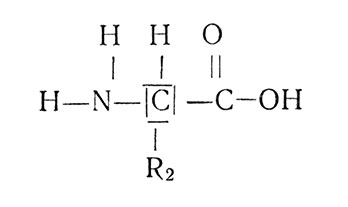
При синтезе белка пептидная связь между аминокислотами замыкается с выделением молекулы воды.
Но, пожалуй, более удивительно то, что из всех имеющихся аминокислот природа выбрала именно 20, и эти 20 - левовращающие, то есть принадлежащие к L-ряду. Это означает, что взаимное расположение радикалов - NH2,-COOH,-R,-H вокруг асимметричного атома углерода (взят в квадрат) у них одинаково. Между прочим, как выяснилось, именно эта особенность помогает некоторым белкам укладываться в правильные спирали. В большинстве белков содержатся почти все аминокислоты. В среднем в состав полипептида входит около 300 аминокислот.
Но в чем же разница между полипептидом и белком? Все белки, как бы они ни различались по своему строению и назначению, становятся работающими только в том случае, если их цепи свернуты в определенные пространственные структуры. Их может быть четыре.
Полипептидная цепь из аминокислот - это первичная структура, причем последовательность аминокислот строго определена для каждого белка. Свернутая в спираль цепь обретает вторичную структуру, свернутая в спираль еще раз - третичную (α-спираль).
Только при третичной структуре (или при четвертичной, когда спирали свертываются уже в клубки) оживает белок. Стоит нарушить эту структуру, развязать таинственные узлы - белок умрет как жизненное начало, превратится в химическое вещество - полипептид.
Молекулярная биология уже нашла ответ на вопрос, кто закручивает белок в клубки и спирали. Они закручиваются сами. Гигантские молекулярные цепи имеют сильнейшую склонность формировать структуры все более сложного порядка. Это доказали Френкель-Конрат в исследованиях на вирусе табачной мозаики и советский ученый Поглазов на белках бактериофага.
Согласно единственной гипотезе, закручивание белков в спирали определяется последовательностью аминокислотных остатков в полипептидных цепях.
Как известно, белки, особенно ферменты, - главные "работники" живой клетки. А работоспособность их, как мы убедились, зависит от последовательности расположения их аминокислот.
Но во всех ли местах белка эта последовательность важна в одинаковой мере? Нет, конечно. Например, в гемоглобине нашли место, где изменение одной-единственной аминокислоты делает белок инвалидом. А что это значит, поймет всякий.
В то же время в белке немало и таких мест, где замена даже нескольких аминокислот нисколько не отражается на его работоспособности. Именно этим отличаются белки с одинаковыми функциями у разных видов жителей нашей планеты. Ведь на Земле нет даже двух одинаковых по аминокислотному составу белков. Так, цепь дыхательного фермента - цитохрома С, состоящая из 104 аминокислот у человека, отличается от цитохрома С обезьяны макаки-резус положением одной аминокислоты, от цитохрома лошади - 12, от цитохрома цыпленка - 14, от цитохрома рыбы-тунца - 22 и, наконец, от цитохрома дрожжевой клетки - 43(!) положениями аминокислот. Такие серьезные различия ни у одного из цито-хромов не оказывают влияние на его активные группы - ведь все эти ферменты у разных животных выполняют одну и ту же работу, и выполняют неплохо!
Биология давно подозревала, что сходство и различие между существами кроется в структуре белка. Но ведь они передаются от родителей к детям через наследственное вещество. Значит, на нем каким-то таинственным способом должны быть "записаны" эти белковые сходства и различия. А когда наука с неоспоримой очевидностью убедилась, что наследственным веществом всей живой материи является ДНК и что один ген ведает синтезом одного белка-фермента, точнее, одной полипептидной цепи, ученые стали искать способ, которым природа "записала" на нуклеиновой кислоте план построения белков.
Они рассуждали примерно так.
Если строение и работа белка определяются порядком чередования 20 разных аминокислот, то в нуклеотидной цепи гена (цистрона), "строящего" этот белок, должен существовать некий код, которым "записана" последовательность аминокислот в молекуле белка.
Что такое код? В науке так называют один из способов передачи информации. Например, в языке слово - это не что иное, как код, которым люди передают информацию друг другу непосредственно и через книги -из поколения в поколение. Код языка состоит из определенного числа букв. В русском языке - 32 буквы, в английском - 26 букв. Сочетание букв - слово-кодирует информацию о предмете, действии, событиях, чувствах и т. д.
Какой код может существовать на нуклеиновых кислотах? Когда стало известно, что они построены из сахара, фосфорной кислоты и четырех оснований, когда Уотсон и Крик показали миру структурную модель ДНК, стало очевидно, что непосредственное участие в кодировании каждой аминокислоты белка могут принимать только молекулы оснований (аденина, гуанина, цитозина и тимина), ибо именно они, причудливо чередуясь, составляют качественное своеобразие ДНК разных видов.
В мире клеток аминокислоты играют роль предметов, основания на ДНК - букв, а сочетание этих оснований - слов, которыми передается информация о предметах (аминокислотах).
Четыре буквы для двадцати предметов... Много это или мало? Вспомните, что в азбуке Морзе всего две буквы - точка и тире - способны передать информацию о 32 буквах алфавита, а современные кибернетические машины работают и вовсе на сочетании 0 и 1. Как создавала природа генетический код на четырехбуквенном алфавите?
Предоставленная самой себе, она стремится к экономии сил и никогда не совершает лишней работы, всецело подчинившись закону минимального действия, который физики открыли еще в XVIII веке. Нет оснований считать, что, составляя код, природа действовала как-то иначе. Перед ней стояла задача - зашифровать двадцать аминокислот с помощью четырех оснований (обозначим их начальными буквами А, Т, Г, Ц). Понятно, что отношение "один к одному" было сразу же отвергнуто: в этом случае все основания могли кодировать лишь 4 аминокислоты, а их - двадцать. Если взять по два основания на одну аминокислоту, то таких сочетаний было бы 16. Этого тоже мало. А вот при кодировании тремя основаниями число сочетаний возрастает до 64. Это уже более чем достаточно. Примерно так рассуждал в 1953 году английский ученый Крик. После него разгадкой таинственного кода на ДНК занялись теоретики - физики и математики. Появилось даже несколько гипотез. Против трехбуквенности кода особых возражений не было. Но вот вопрос: в каком порядке стоят эти "трехбуквенные слова" в "строке" на ДНК? Они могут быть и рядом, и вразбивку, с интервалами. Если интервалов нет, то как природа узнает о том, что кончилось одно "слово" и началось другое? А если интервалы есть, то какое вещество выполняет эту роль? Словом, целая гора загадок.
- Триплеты следуют друг за другом без "запятых", - заявил в 1954 году американский физик Гамов. - Например, в цепи ДНК лежат основания ТАГГЦА. Это значит, что первая аминокислота кодируется триплетом ТАГ, вторая - АГГ, третья - ГГЦ и т. д.
Такой код казался чрезвычайно экономичным. Еще бы! Одно основание участвует в кодировании... трех аминокислот. Это вполне "во вкусе" природы, стремящейся к максимальной "скупости".
Но очень скоро оказалось, что на сей раз экономичность не привлекла ее внимания. Эксперименты один за другим отвергли теорию триплетного перекрывающегося кода, как назвали теорию Гамова.
В самом деле, если принять ее, то три аминокислоты всегда должны следовать друг за другом. Но ни в одном из белков такого не обнаружили. Кроме того, если бы код был перекрывающимся, то изменение одной только буквы вело бы к изменению кода для нескольких аминокислот. Ученые же убедились, что единичная мутация ведет к замене только одной аминокислоты. Так было в белках гемоглобина, вируса табачной мозаики, ферменте триптофансинтетазе.

Схема трех типов кода. АК - аминокислота
Не выдержала критики и другая схема: неперекрывающийся код с промежутками - "запятыми". Больше всех приблизились к истине творцы гипотезы неперекрывающегося кода без "запятых". В ней устранялась возможность считывания соседских аминокислот, однако существовало одно "но", и очень существенное. С какого конца надо считывать? Создатели схемы постулировали, что считывание триплетов при синтезе белка идет слева направо. Но кто поручится, что природа не читает триплеты также справа налево, как древнееврейскую книгу? В этом случае осмысленная при чтении слева направо фраза превращается в абракадабру!
Ученые нашли остроумный способ избавиться от этого "но".
- Из 64 возможных "слов"-триплетов только 20 (по числу аминокислот) имеют смысл, остальные 44-лишены его, - так рассудили английские ученые Крик, Гриффитс и Оргель. - При синтезе белка считывание идет как угодно в обоих направлениях - бессмысленный триплет (тот, что образуется от соединения соседних осмысленных триплетов) "читатель" просто не заметит. К примеру, если ГАТ и ЦЦА - "осмысленные" триплеты и стоят рядом (ГАТЦЦА), то все иные сочетания - АТЦ, ТЦЦ, ЦЦТ, ЦТА - будут лишены смысла: их нет "в словаре".
Такой хитроумный код казался безупречным, и было трудно возразить что-либо против, кроме того, что... он не используется в природе.
Идею ограниченности "словаря" похоронили сами авторы. Но на обломках старой гипотезы они воздвигли стройное здание новой, фундамент которой был прочнее, чем идеи и рассуждения. Это был эксперимент с rII-мутантами фага Т4 Бензера.
Чтобы понять его смысл, надо вспомнить, какие фаги "родятся" при скрещивании двух фагов дикого типа. Правильно, только дикий тип. А вот у Крика такого не получилось. К величайшему его изумлению, от такого "брака" появились на свет не только фаги дикого типа, но и фаги-мутанты типа rII. Правда, в его опыты вкралось одно маленькое отличие: один из диких фагов-родителей был потомком rII-мутанта, неведомо почему вернувшего свой прежний облик.
- Тут что-то не то, - заподозрил Крик и осторожности ради окрестил фаг с "мутантным прошлым" псевдодиким типом. Необходимо отметить, что Крик сам создал это "прошлое". Как он это сделал?
Вначале была одна мутация, и фаг стал rII-мутантом, перестав расти на кишечной палочке К. Потом его обработали профлавином еще раз, и, получив вторую мутацию, он превратился в... дикий тип, то есть стал размножаться на кишечной палочке К. Это было неслыханно! Дважды искалеченный мутацией фаг обретал здоровье. Но для Крика, всецело поглощенного тайной генетического кода, поведение двойных мутаций стало своего рода откровением. И очень может быть, чтобы не упустить мысль, обгонявшую руки, экспериментатор нарисовал "фразы" гипотетических триплетов генетического кода участка rII-хромосомы фага дикого типа. Для удобства он изобразил все триплеты одинаковыми. Ну, что-нибудь вроде этого:
АТЦ АТЦ АТЦ АТЦ АТЦ.
Допустим, рассуждал он, что первая мутация - это вставление где-то в цистроне А лишнего основания. (Ведь профлавин вызывает вставки или нехватки.) Скажем, после второго слова-буквы Ц. Как это подействует на смысл трехбуквенных слов? Первое не изменяется. Второе - тоже. Но с третьего начнется бессмыслица:
АТЦ АТЦ ЦАТ ЦАТ ЦАТ ЦАТ ЦАТ.
Код потерян. Нужный белок не будет синтезирован. А если даже он и появится, то будет не тот, который обычно строит данный цистрон, ибо последовательность аминокислот а белке не та, что нужно.
Возможно, именно такой по сути дела процесс совершается в первом rII-мутанте.
Но вот снова удар - вторая мутация, где-то рядом. Она "вышибла" ну, скажем, в пятом слове из ДНК основание - Т. Смотрите, код возродился на 6-м слове.
АТЦ АТЦ ЦАТ ЦАТ ЦАЦ АТЦ АТЦ.
Очень может быть, что три неверных триплета повлияют на структуру белка, но не сильно. Очень может быть, что функция белка не изменится. Тогда вторая мутация возрождает дикий тип фага; Крик назвал ее супрессорной - подавляющей первую. Но такое возможно лишь в том случае, если код триплетный, без "запятых" и читается только с одного конца.
Эти размышления складывались в голове ученого в грандиозный план похода за тайной генетического кода. Главные его участники - мутанты rII Бензера. Исследователь ранил дикий тип фага Т4 акридиновыми красителями. При таком ударе в полинуклеотидной цепи ДНК либо выпадает нуклеотид, либо включается дополнительный.
Крик не был волшебником и не мог точно знать, что именно, выключение или включение нуклеотида, вызовет первая мутация. Он только предположил, что первая - включение и обозначил ее знаком +. Вторую, супрессорную, ту, что восстанавливает дикий фенотип штамма, он обозначил противоположным знаком-.
Но ведь если вдуматься, то это незнание - не помеха опыту. Важно только, чтобы две мутации фага были разные, чтобы дикий фенотип мог реставрироваться. Очевидно, две мутации одного знака - два выпадения (--) или две вставки (++) нуклеотидов - обеспечат мутантный фенотип.
Эти предсказания в точности воплотились в опытах.
Основой всех рассуждений Крика было то, что каждая аминокислота кодируется триплетом. Но выводы из его первых экспериментов сохранили бы свою силу и в том случае, если бы кодовое число было 4 и даже 5 (хотя трудно себе представить, что экономная природа стала бы растрачивать свои ресурсы столь безрассудно, если она вполне может обойтись числом три). Важно только, чтобы информация, заложенная в цистроне, всегда считывалась с одного и того же конца, "слово" за "словом".
Но ученому хотелось доказать, что кодовое число действительно три, а не четыре и не пять. И это ему удалось. Помогли тройные мутанты одного знака. Он обнаружил удивительную закономерность: одна мутация типа вставки (+) и две мутации того же типа (++) превращали бактерии в rII-мутантный фенотип, а третья такая же мутация (+++) возвращала фаг в "дикое" состояние. Та же закономерность обнаружена для фагов-мутантов с тройными мутациями-нехватками (---).
Тройная мутация восстанавливает функцию... Как это происходит? Давайте возьмем уже знакомый нам гипотетический "текст" кода.
Вот цистрон дикого типа:
АТЦ АТЦ АТЦ АТЦ АТЦ АТЦ АТЦ.
Тот же цистрон, раненный минус мутацией на втором слове. Это - одинарный мутант с выпадением одного основания (Т):
АТЦ АЦА ТЦА ТЦА ТЦА ТЦА ТЦА.
Тот же цистрон, у которого выпало еще одно основание в четвертом слове:
АТЦ АЦА ТЦА ТАТ ЦАТ ЦАТ ЦАТ.
Он тоже мутантный, ибо весь код его спутан. Нужный белок опять не синтезируется.
Но вот в четвертом же слове произошла новая, третья по счету мутация с выпадением основания, и свершилось чудо: код восстановился на пятом слове:
АТЦ АЦА ТЦА ТАЦ АТЦ АТЦ АТЦ.
Так мог сработать только триплетный код. Для четырех- и пятибуквенного кода нужны четыре или пять мутаций одного типа.
Так была доказана триплетность кодового числа. Она подтверждается еще и такими рассуждениями. Помните, один цистрон, по данным Сеймура Бензера, содержит примерно 1000 пар нуклеотидов. Биохимики подсчитали, что один белок-полипептид содержит в среднем до 300 аминокислот. На одну аминокислоту должно приходиться 1000:300=3 основания, то есть кодовое число должно быть 3. И наоборот. Если средний полипептид содержит около 300 аминокислот, то ген должен содержать не менее 1000 пар оснований.
Итак, разные расчеты привели к одному и тому же кодовому числу и к одной и той же длине гена. А раз так, то вполне возможно вычислить и число белков, которые закодированы на ДНК бактерий К12. Ведь если вся ДНК хромосомы несет генетическую информацию и содержит примерно 20 миллионов пар нуклеотидов, а на один белок необходимо 1000 пар, то в хромосоме бактерии можно закодировать программу для синтеза примерно... десяти тысяч различных белков. Эти цифры поразительны. Если невидимая глазом хромосома способна "запомнить" программу синтеза такого количества белков, то программу скольких же белков можно записать на хромосоме человека? Воистину экономичность записи "чертежей" живого организма беспримерна!
Но ведь молекулы ДНК - это гиганты только в мире молекул, и хромосомы человека в "большой жизни" - лишь ничтожная по размеру капелька. А в ней "чертежи" развития сложнейшего организма, все его характерные особенности как вида, в конечном счете вся его жизнь...
Но совершенство работы природы оказалось еще более поразительным, когда исследователи стали раскрывать секреты реализации этой информации - тайны биосинтеза белка в живой клетке.
|
ПОИСК:
|
При использовании материалов активная ссылка обязательна:
http://genetiku.ru/ 'Генетика'